NSX-T 3.0 Design Bootcamp2: NSX Manager 1-1
This is the continuation of my first design blog. In this “NSX-T 3.0 Design Bootcamp: Part 2 – NSX Manager 1-1” blog, let’s look at some of the key design considerations. And the key effort here, I would say to look at the NSX-T manager design process from viewpoints such as
- Logical connectivity: IP access and load balancing
- NSX Manager: failure scenario
Logical Connectivity — IP access and load-balancing
Primarily there are four different design/deployment considerations when you go for the NSX-T manager cluster access.
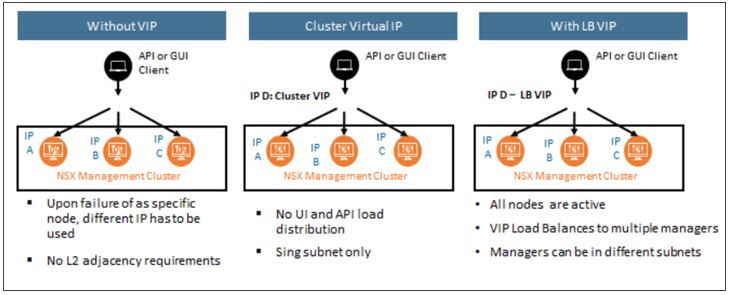
1- NSX-T Management cluster with standalone IP’s: This is the default mode. With this, the nodes in the cluster instances will make use of its own management IP’s for access. These IP’s can be used for operating and administrating the NSX-T manager.
2- NSX-T Management cluster with cluster VIP: From a design recommendation perspective, this method of access is not very ideal. The key reason being, the cluster VIP always ties to one of the NSX-T Manager instances (as active), it does not balance the requests. This poses scalability issues especially with few applications that generate too many API requests against the NSX-T manager. The example would be a cluster like Enterprise PKS running with a large number of Kubernetes clusters.
3- NSX-T Management Cluster with external load balancer Virtual IP: The load balancer VIP can load balances traffic to all NSX-T Manager instances in a round-robin fashion. Even though this incurs additional effort, it can help with the use cases such as using different or same IP subnets and securing access to the cluster
4-TCP/UDP port-requirements: NSX-T Manager uses certain TCP and UDP ports to communicate with other components. Evidently, these L4 port requirements are in this URL and these must be open in the firewall to allow the access
NSX Manager: Failure Scenarios
There are three scenarios to ponder about when you analyze the possible failure cases. And the below diagram explain it well
Scenario1: Any good design should anticipate one component failure. And the scenario of one NSX manager host fails case, the rest of the nodes will be able to take over. Importantly, all the operations and the show will continue without any issues.
Scenario 2: With two nodes missing, the cluster loses quorum and can’t operate as a cluster anymore. The management plane goes into read-only mode. It’s not a disaster, but not a good situation either. You’ll notice things like not being able to connect to the cluster’s VIP anymore. There are some specific steps that need to recover. First, need to deactivate the cluster. We do this by running the “deactivate cluster” manager CLI command on the surviving node: This leaves us with a single, but the operational manager/controller node. We should now be able to login to the manager UI and start recovering the remaining cluster nodes.
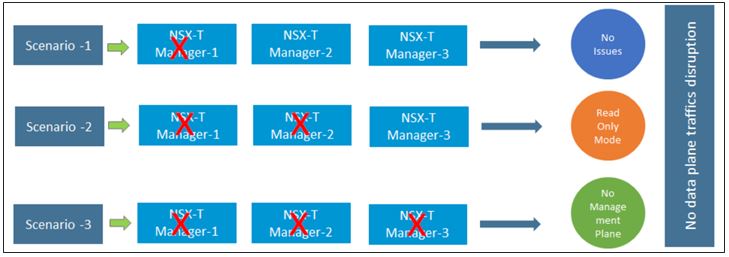
Scenario 3: The assumption here is that you lost all three managers/controller nodes. We are running NSX-T without a management plane (and a central control plane for that matter). Don’t panic! Remember, packets are still flowing as the data plane is still functioning
But of course, it is an emergency situation as the visibility and management capabilities are lost. And need to recover all three nodes from a different site or restore it from the local backup. And for sure when you design you always stick to the principle of single node failure. The remaining two or three node failures could be something to do with the physical facility of the environment. Or due to a critical software/configuration issue on the solution.
Summary and Next Steps
This NSX-T 3.0 Design Bootcamp: Part 2 – NSX Manager 1-1 is mainly around the logical and failure scenarios. In the upcoming blog, we will cover the single and multi-site deployment and also the interoperability and sizing considerations. For more reading on the VMware NSX related blogs please refer to the section VMware. Happy learning
Public Cloud Security Part-1

Choosing the Right Networking Solution is Essential for AI Success
VMware Design Bootcamp-4: NSX-T and AVI Load-balancer
About Author
Muhammad Marakkoottathil(MM)
Expert in the field of SDN, cloud computing, virtualization, active-active data center design & migration. Passionate about helping organizations to achieve their digital transformation objectives with strong 15+ years of experience in design, deployment, and managing heterogeneous network solutions across the industry verticals. Major Industry Certifications: Cisco CCIE, CCDP, VMware VCAP-NV_DESIGN, TOGAF, ITIL, NUTANIX NCSE, Google Cloud Architect, Azure Fundamentals More info please visit my page @ LinkedIn: https://www.linkedin.com/in/contactmm/