AWS IaaS Reference Architecture and Use Cases
It is clear that public cloud infrastructure as a service (IaaS) will have many difference from on-premises environment. Most of the similarity with on-premise infrastructure stops with application, virtual machines and storage and database services. In this “AWS IaaS Reference Architecture and use cases” blog, lets look at few of the primary foundational design principles and some of the key associated use cases.
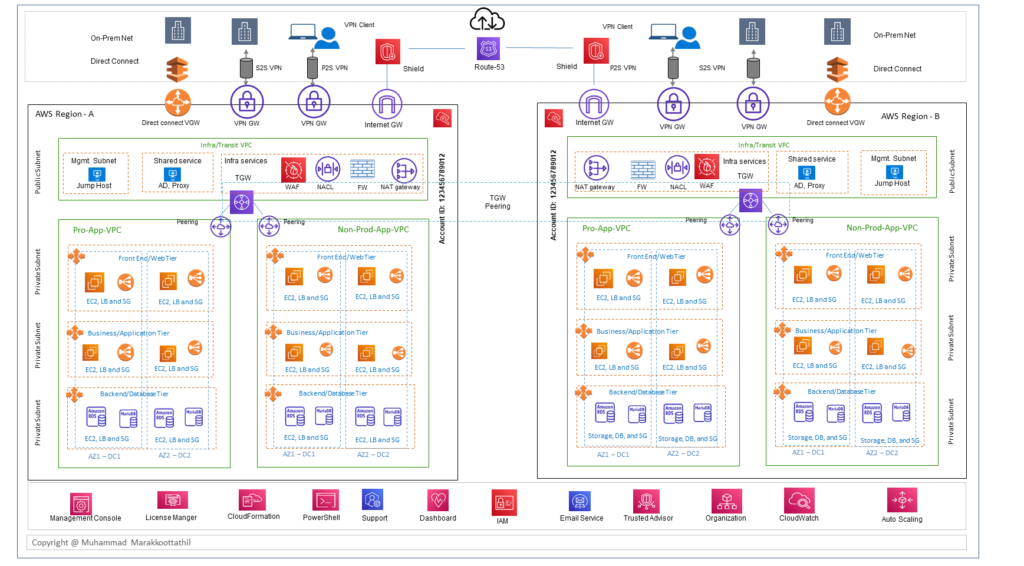
In principle, the overall architecture development is based on majorly in to three key areas.
- Cloud Edge block: this block will be the landing zone for the traffic flow which goes back and forth between the public cloud and the campus, branch office, the internet users and customers. This block primarily includes infrastructure related services such as VPN gateways, Direct connect, NAT gateway, Shield, Route 53, CDN, WAF, TGW, Firewalling and shared services etc.
- Application block: With respect to the organization application landscape this block will have multitier or single tier application and also could be segments such as production, partner application, test and dev environment etc. And could include all the load-sharing and security required for the application.
- Monitoring and governance block: This block majorly comprise of all the single pane management aspects such as dashboard, IAM, advisory service, monitoring solutions such as cloud watch and license manager etc.
Now lets look at the some of the key design use cases for IaaS solutions on AWS
Traffic Routing & Connectivity Options
Lets start with VPC ( virtual private cloud), it provides you with several options for connecting your AWS virtual networks with other remote networks securely. If your users are primarily accessing the application from an office or on premises, you can use a IPsec VPN connection or AWS Direct Connect to connect to the on-premises network and VPC. The routing scale is a major aspects here for an enterprise and one of the key option is to use transit gateways or TGW. And when it comes to the public access, customers can access the web based application using HTTPS and once the traffic land in the cloud edge it can routed through various L4-L7 service through service chaining to do the deep inspection.. etc.
Traffic Distribution and Load Balancing
You can use route 53 DNS to direct users to application hosted on AWS. And use elastic load balancing to distribute incoming traffic across your web servers deployed in multiple Availability Zones. You will find most of the traditional LB functions are available part of AWS ELB and additionally to the cloud specific features & use cases.
High Availability & Redundancy
Each availability zone runs on its own physically distinct, independent infrastructure. The likelihood of two availability zones experiencing a failure at the same time is relatively small, and you can spread your, business application across multiple availability zones to ensure high availability of your application.
In the unlikely event of failure of one AZ, user requests can send through the elastic load balancing to the web server instances in the second availability zone, for example the web servers will failover their requests to the application server instances in the second availability zone. This ensures that your application continues to remain available in the unlikely event of an availability zone failure. In addition to the web and application servers, for example the database on amazon RDS can be deployed in a multi-AZ configuration. When you provision a multi-AZ DB instance, Amazon RDS automatically creates a primary DB instance and synchronously replicates the data to a “standby” instance in a different AZ.
You can also use the Amazon EC2 auto recovery feature to recover failed web, application, and process scheduler server instances in case of failure of the underlying host. EC2 Auto recovery do several checks including loss of power, software issues etc. If it related to hardware failure, the instance will be rebooted on new hardware if necessary, but will retain its instance ID, IP address, Elastic IP addresses, EBS volume attachments, and other configuration details.
Scalability
You can scale up the web, application, and process scheduler servers simply by changing the instance type to a larger instance type.
For example, you can start with an r4.large instance with 2 vCPUs and 15 GiB RAM and scale up all the way to an x1.32xlarge instance with 128 vCPUs and 1,952 GiB RAM.
In the case database deployed on Amazon RDS, you can scale the compute and storage independently. You can scale up the compute simply by changing the DB instance class to a larger DB instance class. This modification typically takes only a few minutes and the database will be temporarily unavailable during this period. You can increase the storage capacity and IOPS provisioned for your database without any impact on database availability.
To meet extra capacity requirements, additional instances of web and application servers can be pre-installed and configured on EC2 instances. And the there is NO charges when EC2 instances are shut down, AWS charges you only for EBS storage
Cross Region Deployment & Disaster Recovery
Even though a single region architecture with multi availability zone deployment might suffice for most use cases, some customers might want to consider a multi-region deployment for disaster recovery (DR) depending on business requirements. For example, there might be a business policy that mandates that the disaster recovery site should be located a certain distance away from the primary site.
You can also use AWS to deploy DR environments for applications running on-premises. In this scenario, the production environment remains on-premises, but the DR environment is on AWS. If the production environment fails, a failover is initiated and users of your application are redirected to the application deployed on AWS.
AWS Security and Compliance
Security in the cloud is slightly different than security in your on-premises data centers. When you move compute systems and data to the cloud, security responsibilities become shared between you and your cloud service provider. In this case, AWS is responsible for securing the underlying infrastructure that supports the cloud, and you are responsible for securing workloads that you deploy in AWS. This shared security responsibility model can reduce your operational burden in many ways, and gives you the flexibility you need to implement the most applicable security controls for your business functions in the AWS environment.
Summary
Architecting public cloud may sound not that complicated but without a strategy in place the it will be hard to justify and control the usage and the bills generated. To summaries your architecture should consider many aspects before moving production workloads in to the cloud such as..
- Middle-mile problem
- Scalable and re-usable architecture
- End to end security, protect your asset and also the shared infrastructure
- Operation and fault tolerance
- Governance and compliance
For more related blogs on the topic – please refer the section “Cloud Computing & services section“ happy learning

Amazon Connect: the cloud contact center solution from AWS
Public Cloud Security Part-1

AWS Associate Solution Architect FAQ’s Part – 1
About Author
Muhammad Marakkoottathil(MM)
Expert in the field of SDN, cloud computing, virtualization, active-active data center design & migration. Passionate about helping organizations to achieve their digital transformation objectives with strong 15+ years of experience in design, deployment, and managing heterogeneous network solutions across the industry verticals. Major Industry Certifications: Cisco CCIE, CCDP, VMware VCAP-NV_DESIGN, TOGAF, ITIL, NUTANIX NCSE, Google Cloud Architect, Azure Fundamentals More info please visit my page @ LinkedIn: https://www.linkedin.com/in/contactmm/