Choosing the Right Networking Solution is Essential for AI Success
In today’s AI age, the world has become increasingly digitally connected, transforming from a data-centric to a network-centric environment. Networks are the neurons of AI operations, facilitating communication, data transfer, and resource sharing across various devices and systems. As the complexity and scale of AI applications grow, so does the demand for efficient and high-performance networking solutions.
This blog covers the key players in AI networking, including Cisco, Juniper Networks, Arista Networks, and Nvidia. Each provides specialized technologies that contribute to AI’s networking needs. It highlights the critical role of networking performance metrics like latency, bandwidth, and scalability in AI workloads. And discusses the importance of Ethernet and Infiniband technologies. The Ultra Ethernet Forum’s efforts to advance Ethernet for AI applications are also noted. Along with innovative networking solutions such as Smart NICs and congestion control mechanisms that help optimize AI infrastructure.
The Importance of Network Choice
The choice of network technology significantly impacts how businesses operate, especially in AI-intensive applications. A well-designed network can optimize data flow, reduce latency, improves job completion time(JCT). And enhance overall system performance and ROI on GPU investment.
| Vendor | Key Advantages |
| Cisco Systems. | Extensive product portfolio – such as DC networking, computing, strong enterprise presence, AI-powered network and security management. |
| Juniper Networks | High-performance routing and switching, Junos OS, AI-driven network analytics. |
| Arista Networks | Single Management with AI-based telemetry and single operating system (EOS) across networking domain, Architecture optimized for AI-based Analytics, Smart NIC capability. Uses AI-optimized Chipset from Broadcom |
| Nvidia – Mellanox(acquired by NVidia) | High-performance GPUs, RDMA (remote direct memory access) and GPU direct, Infiniband famous for HPC and AI use cases, AI-specific networking solutions, software tools for AI development. The InfiniBand network provides a high-performance interconnect between multiple GPU servers as well as providing network connectivity to the shared storage solution. |
AI for Networking, And Networking for AI
The relationship between AI and networking is symbiotic. AI can be used to optimize network performance through intelligent traffic management, anomaly detection, and predictive maintenance. At the same time, networks are essential for enabling AI applications to access and process large datasets efficiently.
The Impact of Network Performance on AI Workloads
Slow or poor network performance can have a detrimental effect on AI workloads. Particularly those involving GPUs. Some of the key parameters to watch especially when building networking solutions for AI are below.
| Key Parameters. | Impact on AI Workloads |
| Latency. | High latency can significantly impact AI workloads that require real-time or near-real-time processing. For example, autonomous vehicles rely on low-latency communication to make timely decisions based on sensor data. |
| Bandwidth | Insufficient bandwidth can limit the speed at which data can be transferred between AI components, such as GPUs and storage devices. This can bottleneck AI training and inference processes. |
| Packet Loss | Packet loss can disrupt data transmission and lead to errors or inconsistencies in AI models. This can impact the accuracy and reliability of AI applications. |
| Jitter | Jitter, or variability in packet arrival times, can affect the synchronization and timing of AI processes. This can be particularly critical for applications that require precise coordination between different components. |
| Reliability | Network reliability is crucial for ensuring that AI workloads can be executed without interruptions. Network failures or outages can lead to downtime and data loss. |
| Scalability | As AI workloads grow in complexity and scale, the network infrastructure must be able to handle increased traffic and demands. A scalable network can accommodate future growth and prevent performance bottlenecks. |
| Security | Network security is essential to protect sensitive data and prevent unauthorized access to AI systems. A compromised network can expose AI models and data to vulnerabilities. |
| Tail Latency | Tail latency, which refers to the longest latency experienced by a small percentage of packets, is a critical metric in AI networking. This metric is critical because even a few delayed packets can significantly impact overall system performance and job completion time to start the next job. |
The Scale of Generative AI and its importance to Networking
Generative AI models, often require massive amounts of computational resources. These models can involve billions or even trillions of parameters. Making them highly demanding in terms of both processing power and network bandwidth.
Several AI-driven networking technologies are emerging to meet the growing demands of AI applications. These technologies leverage network to improve AI performance, efficiency, and security.
| Applications | GPU and other parameters |
| Google Gemini | Extremely large-scale, likely involving thousands of GPUs 1.56 trillion parameters Training time – weeks to months |
| GPT-3 and 4 | Large-scale, but potentially less than Gemini 175 billion parameters and GPT-4 expected to have one trillion parameters Number of GPUs : 10k x v100 Training Time : One Month Training Set Tokens : 300B |
| OpenAI LLaMA | Similar to ChatGPT, but with a focus on natural language understanding 65 billion parameters Training set Tokens: ~1-1.3T Number of GPUs : 2048 x A100 Training time 21 Days |
| Tesla FSD | Moderate-scale, focusing on real-time performance and efficiency Millions to billions (for neural networks used in perception, planning, and control) |
| Microsoft Autopilot | Similar to Tesla FSD, with potential variations based on specific implementations Millions to billions |
As indicated in the above table, most of these applications are using thousands of GPU nodes. Considering, the maximum number of GPU can be hosted on a server chassis are 8 to 16. It takes about 20 to 100 of server nodes interconnected to support even an average-sized AI applications
Below are the examples of some of the key compute vendor chassis and supported GPU count
| Company | Server Model | GPU Count |
| HPE | Apollo 6500 | 16 |
| Dell | PowerEdge XE8545 | 8 |
| Supermicro | SuperServer 8028U-R,SuperServer 1028U-R | 8,16 |
| Lenovo | ThinkSystem SR860 | 8 |
Reason to Choose Ethernet Over Infiniband
Ethernet has become increasingly popular due to its lower cost, widespread adoption, and scalability. It is well-suited for large-scale data centers, offering high bandwidth and a broad ecosystem of tools and vendors. Ethernet’s flexibility and lower operational costs make it ideal for organizations looking to scale AI operations efficiently. On the other hand, InfiniBand is known for its ultra-low latency, which is critical for demanding AI workloads.
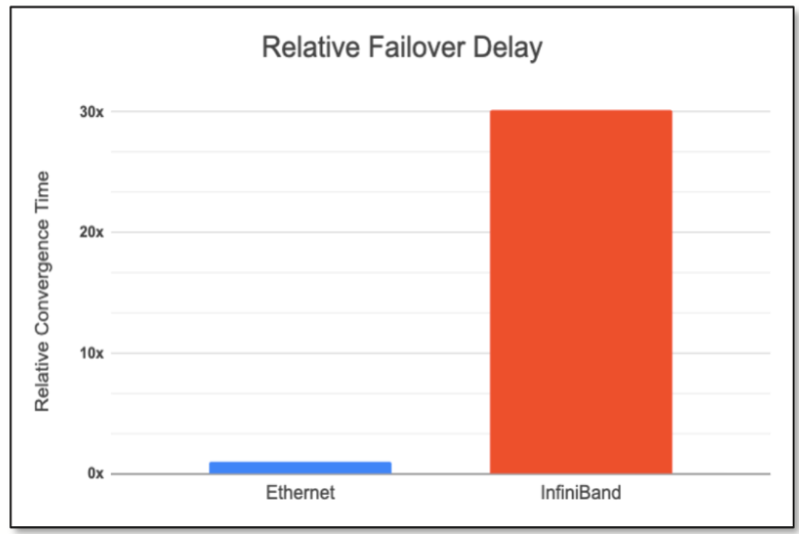
Ethernet has been gaining ground over Infiniband in recent years, particularly in AI and HPC environments. Ethernet’s lower cost, higher scalability, and broader ecosystem make it a more attractive option for many organizations.
| Feature/Use Cases | Ethernet RDMA over Converged Ethernet (RoCE) | Infiniband |
| Protocol | TCP/IP | RDMA |
| Topology | Star, mesh, ring, tree | Point-to-point, switched fabric |
| Latency | Lower than traditional Ethernet, but higher than Infiniband | Lowest latency among networking technologies |
| Bandwidth | High, comparable to traditional Ethernet | High, but typically slightly lower than Ethernet |
| Scalability | Proven, enabling rack-scale and datacenter-scale networks, suitable for large-scale data centers | Scalable, but may have limitations for very large-scale deployments |
| Cost | Lower than Infiniband – proven history of driving down costs through a competitive ecosystem and econnomies of scale | Higher than Infiniband |
| Ecosystem | Broader ecosystem with wider adoption | Smaller ecosystem, primarily used in HPC and supercomputing |
The Ultra Ethernet Forum
The Ultra Ethernet Forum is working to make Ethernet even more suitable for AI applications. By developing new standards and technologies, the forum aims to address the specific requirements of AI workloads, such as low latency, high bandwidth etc. Some of the founding member for Ultra Ethernet Forum include – Arista Networks, Broadcom, Cisco Systems, Intel, Juniper Networks etc.
Key ethernet solutions for the AI Infrastructure
| Solution Name. | Description |
| Smart NICs for AI infrastructure. | Smart NICs (Network Interface Cards) are specialized network adapters that offload network processing tasks from the CPU to the NIC itself. This can significantly improve network performance, reduce CPU utilization, and enhance the overall efficiency of AI applications. Key Features of Smart NICs for AI: Hardware Acceleration: Packet processing, checksum calculation, and encryption/decryption. This offloading can free up CPU resources for AI workloads. RDMA: Allows for direct memory-to-memory data transfers between servers without involving the CPU. This can significantly reduce latency and improve network performance. Virtualization Support: Support virtualization environments, providing network isolation and resource management for multiple virtual machines. |
| NVlink | NVLINK is the NVIDIA advanced interconnect technology for GPU-accelerated computing. Tt enables a GPU to communicate with an NIC on the node through NVLink and then PCI. |
| Modern Congestion control mechanisms | DCQCN = ECN + PFC DLB ( Dynamic Load Balancing) Adjustable Buffer Allocation ECN (Explicit Congetion Notification) : Provides congetion informaiton end-to-end. It adds congestion bits from receiver and it generates and sends a congestion notification packet (CNP) back to sender. When the sender receives the congestion notification, it slows down the flow that matches the notification. This end-to-end process is built in the data path PFC (Priority Flow Control) PFC is used as the primary tool to manage congestion for RoCEv2 transport. PFC is transmitted per-hop, from the place of congestion to the source of the traffic. congestion is signaled and managed using pause frames. |
| RoCEv2 | Generically, remote direct memory access (RDMA) has been a very successful technology for allowing a CPU, GPU, TPU, or other accelerator to transfer data directly from the sender’s memory to the receiver’s memory . RDMA over Converged Ethernet, or RoCE, was created to allow the IBTA’s (InfiniBandTM Trade Association) transport protocol for RDMA to run on IP and Ethernet networks. |
| Multipathing and packet spraying | Packet Spraying technique provides every flow to simultaneously use all paths to the destination – achieving a more balanced use of all network paths – versus ECMP which uses flow hash to map different flows to different paths, this still confines a high throughput flows to one path. |
| Flexible Delivery Order | In AI applications, flexible ordering allows the system to focus on when the last part of a message reaches its destination, eliminating the need for packet reordering. This improves efficiency, especially in bandwidth-intensive operations like packet spraying. |
| End-to-End Telemetry | Optimized congestion control algorithms are enabled by emerging end-to-end telemetry schemes. Congestion information originating from the network can advise the participants of the location and cause of the congestion. Modern switches can facilitate responsive congestion control by rapidly transferring accurate congestion information to the scheduler or pacer – improving the responsiveness and accuracy of the congestion control algorithm. |
| Large Scale, Stability and Reliability | 100G to 800G interfaces and microsecond to nano-second latency, spine-leaf architecture provides solid case for ethernet technologies scales as needed and also provides reliable solutions |
Summary
In the AI-driven world, networking plays a pivotal role as the backbone of infrastructure. Efficient and high-performance networking solutions ensure smooth data flow which is crucial for AI-intensive workloads. A strong network infrastructure can significantly enhance productivity and ROI on GPU investments

CUCM AXL API – Bulk Logout of Extension Mobility Profile Using Python
NSX-T Series: Part 16 – NSX-T Segment T1 Gateway with EDGE Cluster(SR)
AlgoSec – NSPM Solution Quick Review
About Author
Muhammad Marakkoottathil(MM)
Expert in the field of SDN, cloud computing, virtualization, active-active data center design & migration. Passionate about helping organizations to achieve their digital transformation objectives with strong 15+ years of experience in design, deployment, and managing heterogeneous network solutions across the industry verticals. Major Industry Certifications: Cisco CCIE, CCDP, VMware VCAP-NV_DESIGN, TOGAF, ITIL, NUTANIX NCSE, Google Cloud Architect, Azure Fundamentals More info please visit my page @ LinkedIn: https://www.linkedin.com/in/contactmm/
thanks for the blog, it gives an good idea about the networking players and ethernet in AI, however which is best AI solution provider for networking ? how to determine this ????